基于“AI”业务与产品的思路整理

今天,来梳理一下业界是如何做技术相关的内容的。首先,一个基本现实是,大部分的技术都是为了产品服务的。“产品”这个概念,可以泛指一切能够被交付给用户的产物,包括但不限于软件,技术,甚至是知识(将知识写成书籍产品“交付”给读者)。不过,也要意识到:
一味地强调产品思维和视角,会导向“短平快”的产品思路,最后形成技术空心化的结果。
如今,关于“AI落地”的概念也越来越火热,人们希望AI相关的技术能够落地在具体的场景之中,其中,就可以用产品的方式交付给用户,让用户使用AI产品所带来的服务。所以,在这里,对“AI产品”的相关逻辑给梳理一下,背后的基本逻辑和框架什么。
除此之外,当前的大部分的AI模型,其核心驱动仍然是“数据驱动的”(Data-Driven),即,需要大量的数据,如领域数据和专业数据,在这些数据下,才能够生产出领域相关的模型,服务于领域特殊的用户上。
从整个流程上来看,可以分为模型生产与模型服务两个阶段。
- 模型生产:通过相关数据,学习框架(Pytorch)等生产性工具,生产出相关的模型。
- 模型服务:利用已有的模型框架和参数,部署模型,使得相关程序或用户能够调用模型功能提供服务。
同时,这两个阶段,在具体的使用环境中,还能够搜集到用户使用反馈,从而调整模型(产品)功能,以提升模型在该业务或领域上的可用性与并扩展新的功能。
AI业务与产品的流程框架
从机器学习发展史来看,机器学习经过了符号主义,链接主义等内核形式上的变化,而到如今,在以“数据驱动”为主的业务需求探索上,机器学习与“数据”产生了极大的融合。所以,当前讨论AI业务和产品时,是一定需要讨论数据的。接下来,将会简单地从数据的视角来讨论业务和产品方面的内容。
首先,整个业务的技术如果是基于AI的(实际上,并非只有AI,只要是依赖数据的都可以有着类似的框架)。业务与数据会存在这么两个关联性:
- 从数据中发现业务需求;
- 从业务需求中构造数据。
前者,如互联网中,在相关平台上,很容易搜集到用户的行为数据,针对这些数据,就能够抓取到对应的业务需求,比如比如某聊天的流量较多,就可以提取需求为,需要有一个自动化“聊天”,自动化“客服”的需求;后者,在已经针对业务需求描述以后,由于当前的(AI)模型需要数据,所以需要按照业务需求来构造符合需求的数据,比如,某个AI聊天客户,有一些定制化的流程和语录,需要通过数据的方式改变模型,使得模型习得相关的特性。
而这两者的关系,也比较自然,以需求为基准点,前者是在需求之前,后者是在需求之后。
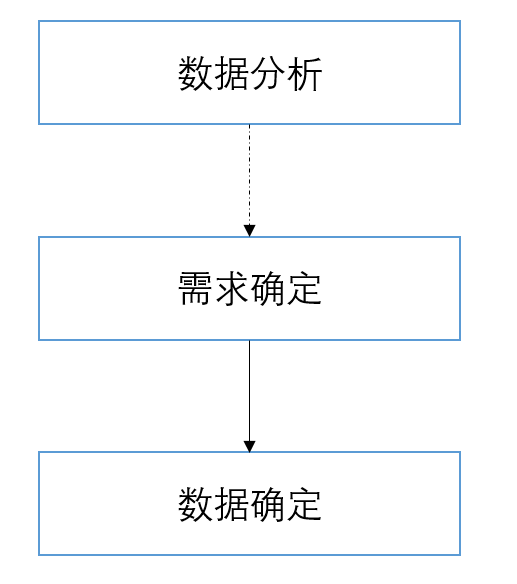
基于数据的通用业务框架
所以,在讨论AI业务与产品之前,首先需要认识到,当前一般通用的产品和业务框架主要都是基于数据为主。首先,需要对数据进行一个简单的描述:
数据是什么
在当前的信息时代,可以说,所有一切能够被当前计算机体系所表示的内容,都可以叫做数据。
在这个背景下,互联网的业务,产品和技术等基于基础计算机设施的模块,自然也是基于数据的模块。一般情况下,互联网的业务和产品都与用户的操作行为强相关,比如各种APP,web网页等。用户与这些产品交互,业务和产品则搜集用户的行为数据,根据行为数据挖掘业务,设计产品。
互联网业务的基本框架
用户交互 -> 交互数据 -> 数据挖掘与分析 -> 下游任务(业务挖掘、产品设计、算法设计等)。
作为这个位置的岗位的“产品经理”,“数据分析师”,他们很容易能够关联起这样的路径“用户行为-产品设计-用户行为”的链路信息,比如,某个页面设计的改变,能够对应用户的停留数据,购买数据等等,这些都能够被记录下来,就能够观察到设计和行为之间的对应关系,进而能够直接理解到一些操作在数据层面的变化。
而当这个逻辑下放到个人的时候,比如自媒体,视频up主,直播,文章等(背后的平台所提供数据分析平台)实际上也是类似的逻辑,通过背后的数据展示,结合自己的文章方向,行文风格的变化等,观察数据上的变化。
所以在这里,也有一些人做出一些警惕:
- 单纯地将用户扁平化为用户行为操作必然是存在以偏概全的风险。
- 通过数据上的分析,捕捉到相关用户的行为特点,反过来利用这些特点以进行牟利。
具体来说,第一点,将用户行为数据等同于用户本身,必然是丢失了极大的信息,而不精准,但是对于第二点,则会有这么一个逻辑,为了业务和产品本身的日活,转化率,点击率等指标以此来收获投资者的青睐,而去设计一些产品交互逻辑,则有可能会导致用户陷入一种被动的情况。
而在数据的背景下,产品形态上的发展,则会有两个方向:
- 新功能的挖掘与探索
- 已有功能的迭代更新。
通过数据的反馈,能够确定产品发展的方向。
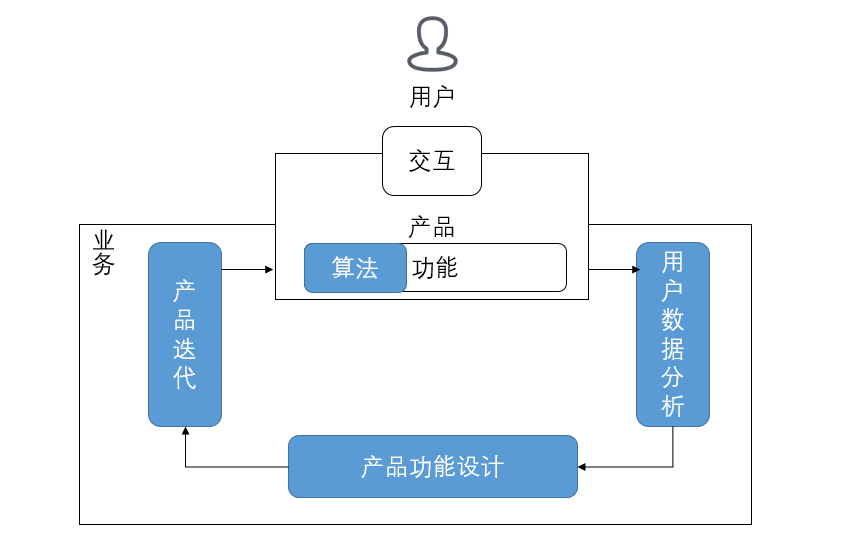
所以,从上述的图例来看,开发/研发岗,会被区分为开发和算法(研发)岗位。从形式上来看,两者实际是是类似的流程,但具体的内容会分为前者主要是根据需求进行软件,硬件功能上的开发,而后者则是针对一些功能上的性能上的优化。
那么,针对下面的话就能够很容易理解了:
算法转开发比较容易,而开发转算法比较难
因为两者的位置都是类似的,接收到的信息都类似,但所做的工作困难程度后者会比前者更加困难。不过根据我的直观来看,可能还是稍有区别,特别是在AI模型下的内容来看,AI的算法设计和软件开发其使用的技术栈已经基本不一样了,而且,相关岗位要求的技能也更加专一,所以其中的转换还是有一定的困难的。
所以这里就存在一点分歧点:产品的视角,就是借助数据等相关工具分析市场,用户倾向,进而设定特定的内容来完成需求从而从市场上获取相关的资金;而技术的视角,就是针对一些能够使用的内容和模块,来完成一些内容。所以在这里就产生了一个矛盾讨论,到底是产品重要,还是技术重要,以及一种岗位——技术管理岗,即,既懂技术,也懂产品(对接),使得技术能够更好地为产品服务。
互联网背景下的AI产品与AI技术的基本框架
最后,也就是当前大家都普遍关注的一个热点——“AI落地”。首先正如上面所述一般,大部分的AI所处在的仍然是一个互联网的背景,所以上述的框架仍然是沿用。那么,是否存在非互联网的业务产品框架的AI技术呢?那肯定是有的,比如类似制造业的AI技术,其对象并非是用户群体,而是工业流程,其中的产品形态和数据形态肯定存在不同。但在这里,主要还是以互联网背景下来进行讨论。
首先,当前的所谓的AI模型,本质上还是数据驱动的模型,这意味着,数据仍然是很重要的一个部分。但对于什么是好数据则难以有一个定义,在这里只是做一些简单的论述。
在AI视角下面,业务被具体化为,根据业务需求,定义模型的输入范式,输出范式,根据这个输入范式和输出范式,定制数据需求,以此来开发或迭代AI模型(产品)。
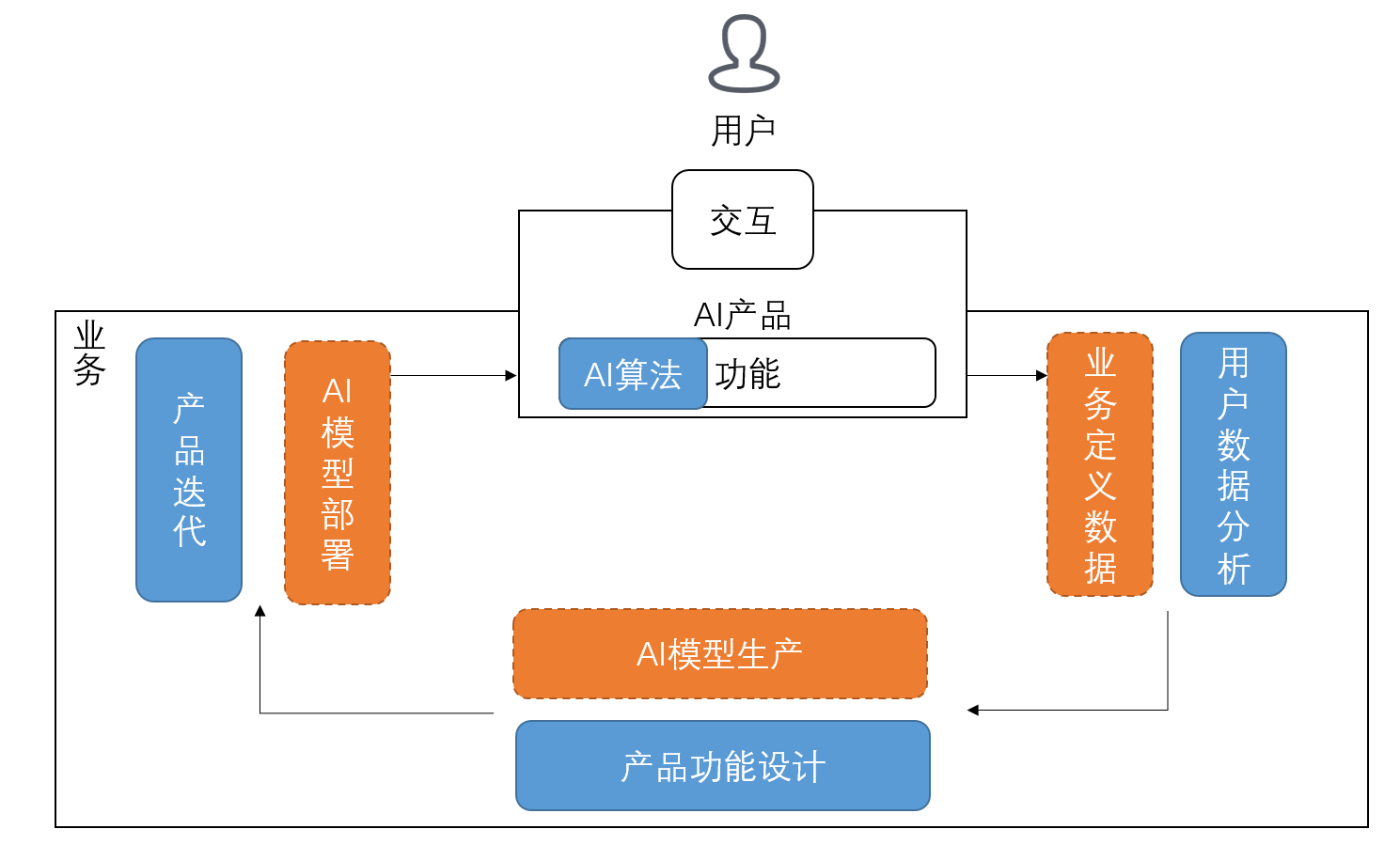
深度学习视角下相关概念梳理
上述主要还是从业务,产品和技术的框架去审视当前的“AI产品”放在什么位置。但是从深度学习的视角下,这里还有一些概念没有梳理清楚。
首先,整个AI产品的流程,可以被分为“模型生产”和“模型部署”这两个环节:
- 模型生产环节,需要对业务定义任务,并用深度学习范式下描述任务,分别有业务指标,评估指标,损失函数指标以及数据采样方式。
- 模型部署环节,需要将模型部署上去,搜集业务指标,在线环境上的数据指标。
个人的一些补充,针对数据集,教科书常见的划分有,训练集,验证集和测试集。实际上,大部分教科书是比较困难说清楚。在这里可以直接理解到。
- 训练集:用于让模型能够学会相关的学习内容
- 验证集:用于评价模型学习状态,欠拟合与过拟合状态。
- 测试集:在线数据直接评估模型。
所以,在这里还能够理解到一点的是:在当前深度学习范式下,大部分任务如果是监督学习(即,对其人类标签),则测试集的评估是比较困难的,大部分情况是需要人工抽检准确率的。
其次,在这里还要注意,损失函数,评估指标也业务指标的三者的联系和区别。
损失函数
其目的有,衡量当前模型状态和训练集之间的“距离”,一定是可微函数,便于梯度下降求导以更新模型参数。
评估指标
一般与业务指标对齐,也可以叫做“性能指标”,即在这个业务场景下,这个模型的性能如何。比如分类准确率(accuracy, ACC),用于评估模型在类别上的准确率,以此来判断模型本身的性能。
业务指标
这一块是直接描述业务状况,比如用户的互动率,日活时长,好评率等。这种甚至和模型性能没有什么关系,有时候甚至可能因为模型性能好但服务不稳定而打差评。
所以,在生产环境之中,评估指标是一个很关键的内容,它肩负起评估模型能力好坏的作用,另一方面又衔接了业务指标——因为,一般情况下会认为,准确率越高,用户越满意的情况。
只不过很多时候,这种认为,并不一定成立,只有在真实场景部署下才能够知道,当前模型的业务指标是什么。有时候为了稳妥,可以采用A/B测试的方式,即新版本的模型和旧版本的模型分不同的流量,针对不同的流程反馈来比较新旧版本模型之间的业务指标好坏,再考虑是否让新版模型上线。
带指令的大规模参数下的AI产品设计思路梳理
当前在大语言模型(LLM)的兴起下,一种基于人类指令(human instruction)模型也被广泛地运用在相关的流程之中。从位置上来看,大量的LLM其实都是大规模参数下的一个子类模型,要理解这个就需要理解LLM的生产过程,即预训练,指令微调和强化学习。
- 预训练(Pretrain):其目的是让模型掌握尽可能预测下一个内容准确的内容。
- 指令微调(SFT):其目的是让模型能够根据指令去“生成”一些内容。
- 强化学习(RL):针对与人类的多轮聊天,让模型能够偏向人类说话的方式生成内容。
所以,现在的LLM实际上是一种Chat类型的大规模参数的文字token模型,它能够批量处理给定的输入,按照指令输出对应的内容。从开发的视角来看,提示词(prompt)本身可以被看做是“开发语言”,然后通过模型训练等方式,对模型功能进行调整,进而达到“功能开发”和“功能优化”这两个目的。
从这个角度来看,当前的模型开发相对会更加容易一点,因为有按照指令生成数据,只不过针对数据生成仍然需要考虑质量好与不好的区别。
现在大量的“应用”,实际上是可以看做”大语言模型LLM”的二次应用设计,个人分析原因是,互联网也是根据用户操作数据,而LLM直接根据用户反馈进行回答,能不能直接端到端直接让用户交互大模型就完事了呢?基于这个思路,大量基于LLM的应用也就开始探索,不管是Agent,RAG,还是现代的Research,AI手机,几乎都可以被看做是LLM的二次应用设计。
而另一方面,模型端上,大家也尝试引入更多的“模态”(Modality),让模型能够根据不同的输入,除了文字输入,还有图片输入,语音输入,甚至是未来的其他输入模态来进行反馈处理。
遗留的问题——数据质量衡量
实际上,所有的流程,都是以计算机,以数据为基础,但是对于数据本身,到底什么是好数据,这一块实际上是需要更深入的理解,但整个框架,只是将数据理解为“传输”的信息,这可能存在一定的问题。
- 标题: 基于“AI”业务与产品的思路整理
- 作者: Wings
- 创建于 : 2026-01-16 21:13:02
- 更新于 : 2026-01-26 21:38:25
- 链接: https://www.wingslab.top/深度学习/当前“AI”的业务思路整理/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。